Вот и случилось то, что я уже давно ожидал/хотел, появилась возможность управлять выводимой геометрией из специального шейдера, я предполагал что это будет какой-то "Control shader" а получился "Task shader", почти угадал)
Да, о чем это я, 19 сентября NVidia презентовала целый пак новых расширений.
Их краткий обзор можно найти здесь:
https://blog.icare3d.org/2018/09/nvidia-turing-vulkanopengl-extensions.html
Большинство из них связаны с VR и RTX и пока интересны только узкому кругу людей.
Но среди них есть одно "революционное" расширение, его важность примерно как переход от FFP к шейдерам. Речь о "Mesh shader": VK_NV_mesh_shader / GL_NV_mesh_shader
Под это дело NVidia выпустила презентацию:
https://devblogs.nvidia.com/introduction-turing-mesh-shaders/
+ видео к ней:
http://on-demand.gputechconf.com/siggraph/2018/video/sig1811-3-christoph-kubisch-mesh-shaders.html
Презентация достаточно длинная, много каких-то примеров псевдо-кода, мало понятных картинок и диаграмм. Мне потребовалось три перекура чтоб дочитать презентацию до конца :)
Для тех же, кто не осилил - попробую вкратце рассказать в чем суть всего этого
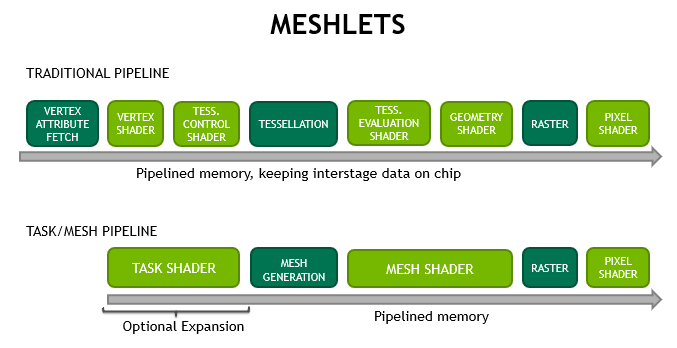
Начнем с первой картинки:
Если сравнивать с традиционным пайплайном, то, как видно с картинки, у нас исчез Vertex Pipeline как класс (Vertex+TessControl + TessEval+Geometry шейдера). Вместо них появилось два новых типа шейдеров - Task Shader + Mesh Shader. Оба шейдера соответствуют "Compute Shader Model", тоесть если вы знакомы с вычислительными шейдерами и приходилось использовать геометрические шейдера, то вы уже значете как этим пользоваться.
В чем суть такой замены - в статье приводится много технической информации, почему это хорошо. Со слов NVidia, сейчас есть пару боттлнеков, в частности:
Собственно сегментирование объектов на кластеры/мешлеты уже давно активно используется. совместно с инстансингом, так как в современных играх количество полигонов на сцене настолько велико, что их просто невозможно вывести в реалтайме, отсечение по объектам через Frustum Culling и Occlusion culling оказывается неэффективным, когда речь идет об объектах на сотни тысяч полигонов, потому разумным решением было разбивать эти объекты на более мелкие части, кластеры, с последующей проверкой видимости каждой из этих частей.
Так, например, сделано в движке от Ubisoft - Anvel Next 2.0:
http://advances.realtimerendering.com/s2015/aaltonenhaar_siggraph2015_combined_final_footer_220dpi.pdf


Будем считать это вступлением, теперь непосредственно что же это за Task Shader и Mesh Shader, как ими пользоваться и что нам это дает.
Ну начнем с главного - оба шейдера используют Compute Shader Model, так что ничего нового тут вам учить не придется. Из важного - в отличии от предыдущего пайплайна, этап растеризации не обязательный. Что это нам дает - мы можем использовать эти шейдеры по своему усмотрению, без привязки к растеризации, по типу вычислительных шейдеров. Но с важным отличием от них, которое мы рассмотрим чуть позже.
Task Shader выполняется первым (смотрим Рис.1). Согласно спецификации:
Ну и теперь переходим к самой интересной/сложной/запутанной части как же формировать этот список индексов для эффективного кеширования.
Это те данные, с которыми будет работать мешлет. Входные данные для него это meshletInfos, выходные - primitiveIndices. Пример в исходной статье написан на С++ для понимания принципа что откуда и зачем. Так как это видно черная магия, то дальше по тексту статьи они дважды меняют названия индексных буферов, забывают включить в пример вершинный буфер и чтоб все было еще понятнее - приводят еще один кусок кода на С++.
Копипастить все это я не буду, просто скажу что в конечном счете, в мешлет нам нужно будет передать SSBO буфер со структурой MeshletDesc, она же по сути Indirect Command Buffer. Ее структура может быть произвольной. Нужно передать исходный индексный буфер, он же vertexIndices и он же (по тексту оригинальной статьи) - triangleIndices. Так же потребуется вершинный буфер, он же vertexBuffer по тексту статьи. Выходные данные, они же primitiveIndices будут записываться в выходной массив gl_PrimitiveIndicesNV. Выглядеть входные данные могут примерно так:
Что происходит дальше, после того как мешлет будет вызван, нужно будет сформировать геометрию (список примитивов и их относительные индексы) для "Primitive Assembly Stage", это хорошо (или не очень) показано вот на этой картинке:
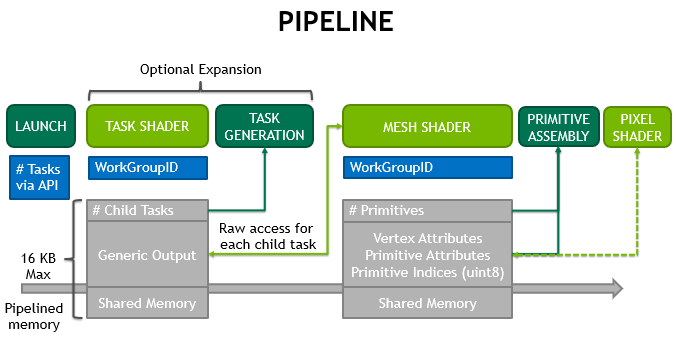
Что нам для этого будет нужно, во-первых пересчитать индексы. Во входном буфере vertexIndices у нас хранятся все индексы всех примитивов. На выход gl_PrimitiveIndicesNV нам нужно переделать пересчитанные индексы относительно новых примитивов. Технически это делается очень просто, имея из TaskShader значение primBegin, далее мы просто вычитаем его как базу из всех индексов, получается что-то по типу:
Таким образом, отсчет индексов продуцируемых примитивов начинается с нуля.
Возможно эта картинка лучше объяснит что происходит с индексами:
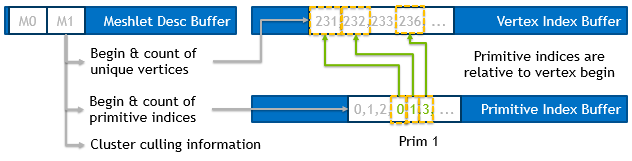
Ну и теперь самое главное - вершинные трансформации никто не отменял. Нам нужно произвести трансформацию каждой из вершин мешлета, примерно так:
Тоесть пройтись по всем вершинам, получить координаты вершины по старым индексам, трансформировать эти координаты используя матрицу трансформации transform (MVP) и записать их в выходной массив, не забыв проапдейтить gl_PrimitiveCountNV, чтоб он указывал на актуальное количество примитивов в мешлете.
Так как это все параллелится, то нужно зне забывать вычислять правильные офсеты с учетом номера потока. Как это делается - можно посмотреть в примере от NVidia. Я все оставил как есть, однако этот пример так же вызывает много вопрос. к примеру - почему используется текстура а не SSBO, зачем они заморачиваются с упаковкой/распаковкой данных, почему нет примера кода распаковки данных и прочее. Так как эта статья скорее информационная чем практическая, то пытаться восстановить все это я не буду, потому просто привожу оригинальный код:
The mesh shader could look something like this when written in parallel fashion:
This example is just a straight-forward implementation. Due to all data fetching being done by the developer, custom encodings, decompression via subgroup intrinsics or shared memory, or temporarly using the vertex outputs are possible to save additional bandwidth.
Спасибо за внимание ;)
Да, о чем это я, 19 сентября NVidia презентовала целый пак новых расширений.
Их краткий обзор можно найти здесь:
https://blog.icare3d.org/2018/09/nvidia-turing-vulkanopengl-extensions.html
Большинство из них связаны с VR и RTX и пока интересны только узкому кругу людей.
Но среди них есть одно "революционное" расширение, его важность примерно как переход от FFP к шейдерам. Речь о "Mesh shader": VK_NV_mesh_shader / GL_NV_mesh_shader
Под это дело NVidia выпустила презентацию:
https://devblogs.nvidia.com/introduction-turing-mesh-shaders/
+ видео к ней:
http://on-demand.gputechconf.com/siggraph/2018/video/sig1811-3-christoph-kubisch-mesh-shaders.html
Презентация достаточно длинная, много каких-то примеров псевдо-кода, мало понятных картинок и диаграмм. Мне потребовалось три перекура чтоб дочитать презентацию до конца :)
Для тех же, кто не осилил - попробую вкратце рассказать в чем суть всего этого
Начнем с первой картинки:
 |
| Рис.1 Meshlets pipeline |
Если сравнивать с традиционным пайплайном, то, как видно с картинки, у нас исчез Vertex Pipeline как класс (Vertex+TessControl + TessEval+Geometry шейдера). Вместо них появилось два новых типа шейдеров - Task Shader + Mesh Shader. Оба шейдера соответствуют "Compute Shader Model", тоесть если вы знакомы с вычислительными шейдерами и приходилось использовать геометрические шейдера, то вы уже значете как этим пользоваться.
В чем суть такой замены - в статье приводится много технической информации, почему это хорошо. Со слов NVidia, сейчас есть пару боттлнеков, в частности:
- Vertex batch creation by the hardware’s primitive distributor scanning the indexbuffer each time even if the topolgy doesn’t change
- Vertex and attribute fetch for data that is not visible (backface, frustum, or sub-pixel culling)
- The previous tessellation shaders were limited to fixed tessellation patterns while geometry shaders suffered from an inefficient threading, unfriendly programming model which created triangle strips per-thread.
Собственно сегментирование объектов на кластеры/мешлеты уже давно активно используется. совместно с инстансингом, так как в современных играх количество полигонов на сцене настолько велико, что их просто невозможно вывести в реалтайме, отсечение по объектам через Frustum Culling и Occlusion culling оказывается неэффективным, когда речь идет об объектах на сотни тысяч полигонов, потому разумным решением было разбивать эти объекты на более мелкие части, кластеры, с последующей проверкой видимости каждой из этих частей.
Так, например, сделано в движке от Ubisoft - Anvel Next 2.0:
http://advances.realtimerendering.com/s2015/aaltonenhaar_siggraph2015_combined_final_footer_220dpi.pdf
{kind=link}
{kind=link}

Будем считать это вступлением, теперь непосредственно что же это за Task Shader и Mesh Shader, как ими пользоваться и что нам это дает.
Note: Все написанное ниже - это моя личная трактовка,"по горячим следам", основанная на презентации и отсутствии доп. информации. Так что некоторые моменты/суждения вполне могут быть ошибочными.
Ну начнем с главного - оба шейдера используют Compute Shader Model, так что ничего нового тут вам учить не придется. Из важного - в отличии от предыдущего пайплайна, этап растеризации не обязательный. Что это нам дает - мы можем использовать эти шейдеры по своему усмотрению, без привязки к растеризации, по типу вычислительных шейдеров. Но с важным отличием от них, которое мы рассмотрим чуть позже.
Task Shader
Начнем с Task Shader - это по моему мнению самое интересное.Task Shader выполняется первым (смотрим Рис.1). Согласно спецификации:
The task shader has no built-in or user-defined input variables other than the built-ins identifying the work group and invocation being executed.Тоесть каких-то особых типов входных данных для него нет, используются все доступные для Compute Shader средства для получение информации о таске - из SSBO, текстур и прочего, тоесть полная свобода действий для программиста.
The task shader can use that information to read properties of the geometry associated with the task from memory, using shader storage buffers, textures, or other resources.
Note: P.S. Копнув чуть глубже, обнаружилось что все же входные данные для Task Shader таки есть, это две встроенные переменные:
in uint gl_MeshViewCountNV;
in uint gl_MeshViewIndicesNV[];
Из той же спецификации:
When using the multi-view API feature, the primitives emitted by the mesh shader will be processed separately for ach enabled view and sent to a different layer of a layered render target.
Так как "multi-view" выходит за рамки данной статьи (и знаний автора), то это мы пока пропустим :)
На практике такая свобода означает что эти таски вообще могут быть никак не связаны с геометрией, тоесть мы можем ставить произвольные задачи в очередь на GPU!
Для чего это задумывалось и как это работает - по gl_GlobalInvocationID.x, мы берем данные из какого-то источника, назовем его meshletDescs, каким-то образом его обрабатываем (к примеру - делаем проверку видимости кластера/мешлета) и на основе этой информации - вызываем Mesh Shader, который подготовит геометрию к растеризации (или выполнит другие нужные нам действия).
В статье, для куллинга приводят ссылку на дескриптор такого вот формата:

Это тот самый массив дескрипторов, используемый в коде Task Shader:
uvec4 desc = meshletDescs[gl_GlobalInvocationID.x];
Плюс - проверка видимости - earlyCull(desc);
Но интерес для нас представляют не входные данные, какие могут быть абсолютно любыми, а выходные данные. Ко встроенным выходным данным относится лишь встроенная переменная gl_TaskCountNV. Также для Task Shader и Mesh Shader добавился новый интерфейсный блок taskNV, который можно использовать для передачи данных о сабтасках в вызываемый Mesh Shader:
Эти данные, совместно с gl_TaskCountNV определяют сколько будет создано последовательных Mesh Shader для этой таски и какие данные будут переданы в них (baseID+SubIDs). Собственно по этим данным уже в Mesh Shader можно будет получить информацию из входного буфера (к примеру, indirect command buffer), о том, какую именно геометрию рендерить:
На этом пожалуй и закончим с Task Shaders, в отсутствии драйверов и примеров, за дальнейшими разъяснениями обращайтесь к оригиналу статьи и спецификации.
Как мы уже выяснили, Mesh Shader это группа сабтасков, создаваемая в Task Shader. При этом все чаилды (Mesh Shader) одной группы (таски) процессятся параллельно. Как это работает с точки зрения топологии выполнения показано на этой картинке:
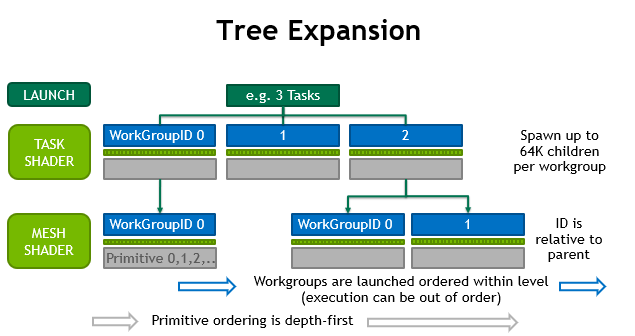
Не хотелось бы плодить еще кучи "псевдокода", их в статье и так хватает, но все же покажу пример связи между Task Shader и Mesh Shader:
В данном примере, роль Task Shader выполняет цикл, который проходит по всем объектам и каждая итерация которого вызывает Mesh Shader (glDraw*) с параметрами объекта. Тоесть концептуально ничего сложного, просто перенести этот цикл на уровень шейдеров. Но только этим работа Mesh Shader не ограничивается. Так как NVidia исключила целый ряд промежуточных стадий (Vertex Attribute Fetch, Vertex, TessControl + TessEval, Geometry), то эти задачи по сути перекладывается на пользователя и реализуются как раз в Mesh Shader.
Начнем с самого шейдера, входными данными для него являются только встроенные переменные gl_MeshViewCountNV и gl_MeshViewIndicesNV. Как я уже упоминал ранее - эти переменные используются в multi-view api и в оригинальной статье не упоминаются. За деталями идем в спецификацию.
Так же входными для Mesh Shader являются данные, переданные из Task Shader через интерфейсный блок taskNV. Как уже было сказано ранее - эти данные уникальны для вызываемых из Task Shader'а группы Mesh Shader'ов.
К выходным данным относятся встроенные переменные gl_PrimitiveCountNV и gl_PrimitiveIndicesNV[]. Так же можно указывать дополнительные, per-vertex и per-primitive атрибуты через структуры gl_MeshPerVertexNV и gl_MeshPerPrimitiveNV. Данные структуры объявлены так:
Вдобавок к этим данным, можно указывать per-vertex атрибуты:
Структура такого шейдера/мешлета выглядит так:
Как выбирать размер GroupSize увы рекомендаций пока нет, кроме указанного в примере "local_size_x=32", но есть ограничение - workgroup всегда одномерный.
Для чего это задумывалось и как это работает - по gl_GlobalInvocationID.x, мы берем данные из какого-то источника, назовем его meshletDescs, каким-то образом его обрабатываем (к примеру - делаем проверку видимости кластера/мешлета) и на основе этой информации - вызываем Mesh Shader, который подготовит геометрию к растеризации (или выполнит другие нужные нам действия).
В статье, для куллинга приводят ссылку на дескриптор такого вот формата:

Это тот самый массив дескрипторов, используемый в коде Task Shader:
uvec4 desc = meshletDescs[gl_GlobalInvocationID.x];
Плюс - проверка видимости - earlyCull(desc);
Но интерес для нас представляют не входные данные, какие могут быть абсолютно любыми, а выходные данные. Ко встроенным выходным данным относится лишь встроенная переменная gl_TaskCountNV. Также для Task Shader и Mesh Shader добавился новый интерфейсный блок taskNV, который можно использовать для передачи данных о сабтасках в вызываемый Mesh Shader:
taskNV out Task {
uint baseID;
uint8_t subIDs[GROUP_SIZE];
} OUT;
gl_TaskCountNV - defines the number of subsequent mesh shader work groups to generate upon completion of the task shader.
Эти данные, совместно с gl_TaskCountNV определяют сколько будет создано последовательных Mesh Shader для этой таски и какие данные будут переданы в них (baseID+SubIDs). Собственно по этим данным уже в Mesh Shader можно будет получить информацию из входного буфера (к примеру, indirect command buffer), о том, какую именно геометрию рендерить:
uint meshletID = IN.baseID + IN.subIDs[gl_WorkGroupID.x]; uvec4 desc = meshletDescs[meshletID];
Note: Тут хотелось бы уточнить, что этот "uvec4 desc" совместно с "meshletDescs" это не то же самое что и в Task Shader, по каким-то причинам они назвали разные вещи одинаковыми именами. В Mesh Shader эта структура по сути описывает командный буфер и в примере определена как:
struct MeshletDesc {
uint32_t vertexCount; // number of vertices used
uint32_t primCount; // number of primitives (triangles) used
uint32_t vertexBegin; // offset into vertexIndices
uint32_t primBegin; // offset into primitiveIndices
}
Но интерес здесь как раз представляет написанное мелким шрифтом:
Children of the task T are guaranteed to be launched after children of task T-1.Что это значит - это значит что таски выполняются строго последовательно. Для чего это может быть использовано на практике - для вычисления трансформаций графа сцены или для обхода дерева поиска и прочего, что раньше приходилось делать на CPU или извращаться многопроходными вычислительными шейдерами. Сейчас это решается очень элегантно через Task Shader. О чем собственно и пишут в спецификации:
The task shader should be used for dynamic work generation or filtering.
With rasterization disabled, both task and mesh shaders can be used to implement basic compute-trees.
На этом пожалуй и закончим с Task Shaders, в отсутствии драйверов и примеров, за дальнейшими разъяснениями обращайтесь к оригиналу статьи и спецификации.
Mesh Shader
Немного разобравшись с Task Shader теперь можно переходить к Mesh Shader.Как мы уже выяснили, Mesh Shader это группа сабтасков, создаваемая в Task Shader. При этом все чаилды (Mesh Shader) одной группы (таски) процессятся параллельно. Как это работает с точки зрения топологии выполнения показано на этой картинке:
Не хотелось бы плодить еще кучи "псевдокода", их в статье и так хватает, но все же покажу пример связи между Task Shader и Mesh Shader:
struct MeshletDesc { uint32_t vertexCount; // number of vertices used uint32_t primCount; // number of primitives (triangles) used uint32_t vertexBegin; // offset into vertexIndices uint32_t primBegin; // offset into primitiveIndices } std::vector<meshletdesc> meshletInfos; for (const meshletdesc& desc : meshletInfos) { glDrawElementsBaseVertex(GL_TRIANGLE, desc.primCount, GL_UNSIGNED_INT, (GLvoid *)desc.primBegin, desc.vertexBegin); }
В данном примере, роль Task Shader выполняет цикл, который проходит по всем объектам и каждая итерация которого вызывает Mesh Shader (glDraw*) с параметрами объекта. Тоесть концептуально ничего сложного, просто перенести этот цикл на уровень шейдеров. Но только этим работа Mesh Shader не ограничивается. Так как NVidia исключила целый ряд промежуточных стадий (Vertex Attribute Fetch, Vertex, TessControl + TessEval, Geometry), то эти задачи по сути перекладывается на пользователя и реализуются как раз в Mesh Shader.
Начнем с самого шейдера, входными данными для него являются только встроенные переменные gl_MeshViewCountNV и gl_MeshViewIndicesNV. Как я уже упоминал ранее - эти переменные используются в multi-view api и в оригинальной статье не упоминаются. За деталями идем в спецификацию.
Так же входными для Mesh Shader являются данные, переданные из Task Shader через интерфейсный блок taskNV. Как уже было сказано ранее - эти данные уникальны для вызываемых из Task Shader'а группы Mesh Shader'ов.
К выходным данным относятся встроенные переменные gl_PrimitiveCountNV и gl_PrimitiveIndicesNV[]. Так же можно указывать дополнительные, per-vertex и per-primitive атрибуты через структуры gl_MeshPerVertexNV и gl_MeshPerPrimitiveNV. Данные структуры объявлены так:
out gl_MeshPerVertexNV {
vec4 gl_Position;
perviewNV vec4 gl_PositionPerViewNV[]; // NVX_multiview_per_view_attributes
float gl_PointSize;
float gl_ClipDistance[];
perviewNV float gl_ClipDistancePerViewNV[][];
float gl_CullDistance[];
perviewNV float gl_CullDistancePerViewNV[][];
} gl_MeshVerticesNV[];
perprimitiveNV out gl_MeshPerPrimitiveNV {
int gl_PrimitiveID;
int gl_Layer;
perviewNV int gl_LayerPerViewNV[];
int gl_ViewportIndex;
int gl_ViewportMask[]; // NV_viewport_array2
perviewNV int gl_ViewportMaskPerViewNV[][];
} gl_MeshPrimitivesNV[];
Вдобавок к этим данным, можно указывать per-vertex атрибуты:
out Interpolant {
vec2 uv;
} OUT[]; // [max_vertices]
Note: Благодаря новому расширению NV_fragment_shader_barycentric, появилась возможность во фрагментном шейдере получать "сырые" вершинных атрибутов и уже вручную их интерполировать.Каждый Mesh Shader, он же meshlet, привыкаем к терминологии NV, может представлять произвольное количество выходных вершин и примитивов. Нет никаких ограничений на связанность этих примитивов, однако, их количество должно быть не более максимального значения, указанного в коде шейдера.
Структура такого шейдера/мешлета выглядит так:
// Set the number of threads per workgroup (always one-dimensional). // The limitations may be different than in actual compute shaders. layout(local_size_x=32) in; // the primitive type (points,lines or triangles) layout(triangles) out; // maximum allocation size for each meshlet layout(max_vertices=64, max_primitives=126) out; // the actual amount of primitives the workgroup outputs // ( <= max_primitives) out uint gl_PrimitiveCountNV; // an index buffer, using list type indices (strips are not supported here) out uint gl_PrimitiveIndicesNV[]; // [max_primitives*3 for triangles]
Как выбирать размер GroupSize увы рекомендаций пока нет, кроме указанного в примере "local_size_x=32", но есть ограничение - workgroup всегда одномерный.
Так же как и в геометрическом шейдере, нужно указать какой тип примитивов мы выдаем, делается это через "layout(triangles) out;". В этом примера из статьи используются именно
triangles, так как triangle strips не поддерживаются.
Еще веселее обстоят дела с max_vertices и max_primitives. Это определяет как много вершин/примитивов будет создано мешлетом, точнее - сколько под это выделить памяти. Из рекомендации NVidia:
We recommend using up to 64 vertices and 126 primitives. The ‘6’ in 126 is not a typo. The first generation hardware allocates primitive indices in 128 byte granularity and and needs to reserve 4 bytes for the primitive count. Therefore 3 * 126 + 4 maximizes the fit into a 3 * 128 = 384 bytes block. Going beyond 126 triangles would allocate the next 128 bytes. 84 and 40 are other maxima that work well for triangles.Тоесть чтоб эффективно использовать 128 байтные блоки памяти рекомендуется количество примитивов *3 делать кратным 128, минус 4 байта на счетчик количества примитивов. Таким образом рекомендуемыми значениями могут быть 40, 84 или 126 примитивов. Сколько можно указать максимум примитивов - зависит от количества памяти используемой мешлетом и сколько их может работать в параллели. Конкретные цифры не приводятся, но рекомендуют не злоупотреблять:
...we recommend you be as efficient as possible in the way all outputs or shared memory is usedНу и на выходе мешлета у нас gl_PrimitiveCountNV и gl_PrimitiveIndicesNV[]. В gl_PrimitiveCountNV указывается актуальное количество выводимых примитивов, а в gl_PrimitiveIndicesNV - индексы этих примитивов
[Offtop on]
Недаром говорят, все новое это хорошо забытое старое. Так и здесь. На самом деле идея с оптимизацией топологии объекта для максимального реюза вершинного кеша не нова, соответствующие рекомендации и библиотека nvTriStrip, оптимизирующая данные под этот кеш, были еще в 2000-х годах, но основной проблемой было как раз определить оптимальный размер этого вершинного кеша. Так как в API OpenGL не было никаких способов его определить. а его размер очень сильно варьировался между видеокартами даже одного вендора, то получалось что оптимизировав топологию под одну видеокарту и получив 5-10% прирост производительности, на другой видеокарте можно было получить 10-15% падение производительности из-за неэффективного использования кеша. Потому об этой технике постепенно начали забывать, особенно с активным ростом вычислительных мощностей видеокарт.
Так как сейчас пользователь может сам контролировать размер этого кеша, то оптимизация топологии вновь становится актуальной, правда всплывает новая проблема - не всегда оптимальная для вершинного кеша топология оказывается оптимальной для вывода с использованием отсечения невидимых участков, но об этом позже.
P.S. В статье приводится ссылка на Tom Forsyth’s linear-speed optimizer, пока не пробовал, но выглядит интересно.
[Offtop off]
P.S. В статье приводится ссылка на Tom Forsyth’s linear-speed optimizer, пока не пробовал, но выглядит интересно.
[Offtop off]
Note: Дальше вся происходящая магия будет взята целиком из статьи, так как придумывать что-то свое еще пока рано.Магия начинается здесь:
struct MeshletDesc { uint32_t vertexCount; // number of vertices used uint32_t primCount; // number of primitives (triangles) used uint32_t vertexBegin; // offset into vertexIndices uint32_t primBegin; // offset into primitiveIndices } std::vector<meshletdesc> meshletInfos; std::vector<uint8_t> primitiveIndices; // use uint16_t when shorts are sufficient std::vector<uint32_t> vertexIndices;
Это те данные, с которыми будет работать мешлет. Входные данные для него это meshletInfos, выходные - primitiveIndices. Пример в исходной статье написан на С++ для понимания принципа что откуда и зачем. Так как это видно черная магия, то дальше по тексту статьи они дважды меняют названия индексных буферов, забывают включить в пример вершинный буфер и чтоб все было еще понятнее - приводят еще один кусок кода на С++.
Копипастить все это я не буду, просто скажу что в конечном счете, в мешлет нам нужно будет передать SSBO буфер со структурой MeshletDesc, она же по сути Indirect Command Buffer. Ее структура может быть произвольной. Нужно передать исходный индексный буфер, он же vertexIndices и он же (по тексту оригинальной статьи) - triangleIndices. Так же потребуется вершинный буфер, он же vertexBuffer по тексту статьи. Выходные данные, они же primitiveIndices будут записываться в выходной массив gl_PrimitiveIndicesNV. Выглядеть входные данные могут примерно так:
struct MeshletDesc { uint vertexCount; // number of vertices used uint primCount; // number of primitives (triangles) used uint vertexBegin; // offset into vertexIndices uint primBegin; // offset into primitiveIndices } layout(std430, binding = 1) buffer MeshletDescriptors { MeshletDesc meshletInfos[]; }; layout(std430, binding = 2) buffer Indices { uint vertexIndices[]; }; layout(std430, binding = 3) buffer Vertices { vec4 vertexBuffer[]; };
Что происходит дальше, после того как мешлет будет вызван, нужно будет сформировать геометрию (список примитивов и их относительные индексы) для "Primitive Assembly Stage", это хорошо (или не очень) показано вот на этой картинке:
Что нам для этого будет нужно, во-первых пересчитать индексы. Во входном буфере vertexIndices у нас хранятся все индексы всех примитивов. На выход gl_PrimitiveIndicesNV нам нужно переделать пересчитанные индексы относительно новых примитивов. Технически это делается очень просто, имея из TaskShader значение primBegin, далее мы просто вычитаем его как базу из всех индексов, получается что-то по типу:
for (int p = 0; p < primCount; p++){ gl_PrimitiveIndicesNV[p*3+0] = vertexIndices[meshlet.vertexBegin+0] - meshlet.primBegin; gl_PrimitiveIndicesNV[p*3+1] = vertexIndices[meshlet.vertexBegin+1] - meshlet.primBegin; gl_PrimitiveIndicesNV[p*3+2] = vertexIndices[meshlet.vertexBegin+2] - meshlet.primBegin; }
Таким образом, отсчет индексов продуцируемых примитивов начинается с нуля.
Возможно эта картинка лучше объяснит что происходит с индексами:
Ну и теперь самое главное - вершинные трансформации никто не отменял. Нам нужно произвести трансформацию каждой из вершин мешлета, примерно так:
for (int v = 0; v < meshlet.vertexCount; v++){ int vertexIndex = vertexIndices[meshlet.vertexBegin + v]; vec4 vertex = vertexBuffer[vertexIndex]; gl_MeshVerticesNV[v].gl_Position = transform * vertex; }
Тоесть пройтись по всем вершинам, получить координаты вершины по старым индексам, трансформировать эти координаты используя матрицу трансформации transform (MVP) и записать их в выходной массив, не забыв проапдейтить gl_PrimitiveCountNV, чтоб он указывал на актуальное количество примитивов в мешлете.
Так как это все параллелится, то нужно зне забывать вычислять правильные офсеты с учетом номера потока. Как это делается - можно посмотреть в примере от NVidia. Я все оставил как есть, однако этот пример так же вызывает много вопрос. к примеру - почему используется текстура а не SSBO, зачем они заморачиваются с упаковкой/распаковкой данных, почему нет примера кода распаковки данных и прочее. Так как эта статья скорее информационная чем практическая, то пытаться восстановить все это я не буду, потому просто привожу оригинальный код:
The mesh shader could look something like this when written in parallel fashion:
void main() { ... // As the workgoupSize may be less than the max_vertices/max_primitives // we still require an outer loop. Given their static nature // they should be unrolled by the compiler in the end. // Resolved at compile time const uint vertexLoops = (MAX_VERTEX_COUNT + GROUP_SIZE - 1) / GROUP_SIZE; for (uint loop = 0; loop < vertexLoops; loop++){ // distribute execution across threads uint v = gl_LocalInvocationID.x + loop * GROUP_SIZE; // Avoid branching to get pipelined memory loads. // Downside is we may redundantly compute the last // vertex several times v = min(v, meshlet.vertexCount-1); { int vertexIndex = texelFetch( vertexIndexBuffer, int(meshlet.vertexBegin + v)).x; vec4 vertex = texelFetch(vertexBuffer, vertexIndex); gl_MeshVerticesNV[v].gl_Position = transform * vertex; } } // Let's pack 8 indices into RG32 bit texture uint primreadBegin = meshlet.primBegin / 8; uint primreadIndex = meshlet.primCount * 3 - 1; uint primreadMax = primreadIndex / 8; // resolved at compile time and typically just 1 const uint primreadLoops = (MAX_PRIMITIVE_COUNT * 3 + GROUP_SIZE * 8 - 1) / (GROUP_SIZE * 8); for (uint loop = 0; loop < primreadLoops; loop++){ uint p = gl_LocalInvocationID.x + loop * GROUP_SIZE; p = min(p, primreadMax); uvec2 topology = texelFetch(primitiveIndexBuffer, int(primreadBegin + p)).rg; // use a built-in function, we took special care before when // sizing the meshlets to ensure we don't exceed the // gl_PrimitiveIndicesNV array here writePackedPrimitiveIndices4x8NV(p * 8 + 0, topology.x); writePackedPrimitiveIndices4x8NV(p * 8 + 4, topology.y); } if (gl_LocalInvocationID.x == 0) { gl_PrimitiveCountNV = meshlet.primCount; }
Воу, хоть что-то новое для оптимизации придумали)
ОтветитьУдалитьСпасибо за информацию :)