Переводя следующую главу спецификации я столкнулся с несколькими проблемами.
По всей видимости, начиная с главы "6.4 Execution And Memory Dependencies", у спецификации поменялся автор - два слова связать не может, постоянно пережовывает одно и тоже, сплош и рядом тафтология, предложения закручивает так, что и 100-грамм не помогает, вообщем текст ужасный, местами я при перечитывании переведенного просто удалял целые абзацы, заменяя их одной фразой.
Но это пол-беды, не знаю кто виноват, этот же автор или еще кто, но в этой главе явно нарушен порядок изложения материала (да, я понимаю что это спецификация, но все же), вначале разжовываются сценарии, а только через пару глав рассказывается что же такое эти dependency, renderpass, subpass, pipeline stages и многое другое. В результате теряется суть написанного и весь перевод главы становится абсолютно бессмысленным.
Можно было бы оставить "как есть", и в конце приписать что-то типа "не виноватая-я, оно так и было" и предложить вернуться к этой главе спустя сотню страничек спеки, но я все же постараюсь сделать это повествование логичным, хоть и придется отойти от порядка изложения определенного в спецификации, в том числе и используя "сторонние" материалы.
По всей видимости, начиная с главы "6.4 Execution And Memory Dependencies", у спецификации поменялся автор - два слова связать не может, постоянно пережовывает одно и тоже, сплош и рядом тафтология, предложения закручивает так, что и 100-грамм не помогает, вообщем текст ужасный, местами я при перечитывании переведенного просто удалял целые абзацы, заменяя их одной фразой.
Но это пол-беды, не знаю кто виноват, этот же автор или еще кто, но в этой главе явно нарушен порядок изложения материала (да, я понимаю что это спецификация, но все же), вначале разжовываются сценарии, а только через пару глав рассказывается что же такое эти dependency, renderpass, subpass, pipeline stages и многое другое. В результате теряется суть написанного и весь перевод главы становится абсолютно бессмысленным.
Можно было бы оставить "как есть", и в конце приписать что-то типа "не виноватая-я, оно так и было" и предложить вернуться к этой главе спустя сотню страничек спеки, но я все же постараюсь сделать это повествование логичным, хоть и придется отойти от порядка изложения определенного в спецификации, в том числе и используя "сторонние" материалы.
Стоило мне принять это решение как тут же попалась статья от AMD по этим самым renderpass-ам, с которых и начнется повествование.
Ну и под конец хотелось бы добавить картинку из их предыдущей статьи, предполагалось что так будет понятнее :)
Vulkan Renderpasses
Vulkan™ это высокопроизводительное графическое API с малым оверхедом, разработанное чтобы позволить передовым приложениям выжать максимум из современных GPU. Там, где традиционные API представляют абстракции, которые ведут себя так, как будто команды выполняются незамедлительно, Вулкан использует модель, которая описывает то, что происходит на самом деле, что фактически GPU выполняют команды, помещенные в память, потенциально не упорядоченно, и что эти команды и где эти буферы команд могут билдиться параллельно в нескольких программных потоках. Боле того, большие куски взаимосвязанных состояний предоставляются драйверу одновременно через объекты состояния. Это предоставляет драйверу возможность полностью оптимизировать состояние GPU задолго до начала рендеринга чтоб максимизировать производительность без риска подтормаживания и других проблем, связанных с JIT оптимизацией. Конечный результат это меньшее, более постоянное время кадра и меньший CPU оверхед, что означает больше времени CPU для ваших задач.
Наиболее значимые изменения, относительно AMD Mantle, пришли с мобильного сегмента, где преимущественно используется тайловая архитектура GPU? чтоб минимизировать трафик с чипа в память, что в конечном счете экономит энергию.
Среди предложенного мобильными участниками был renderpass - объект, разработанный для передачи драйверу высокоуровневой структуры кадра. Тайловые драйвера GPU могут использовать эту информацию чтоб определить когда передавать данные в/из чипа, следует ли очищать данные в памяти или удалять содержимое буферов тайлов, и даже делать такие вещи как определение размера выделяемой памяти, используемой для биндинга и других внутренних операций. Это то, чего не имела Mantle и чего нет в Direct3D® 12.
To Tile or Not To Tile
Тайловое GPU берет пакет геометрии и определяет в какую часть буфера кадра попадет эта геометрия, и затем, для каждого региона буфера кадра рендерится та часть геометрии, которая попадает в этот тайл. Это делает доступ к фреймбуферу когерентным и в большинстве случаев позволяет GPU закончить рендеринг одного тайла фрейма целиком на чипе до прехода к следующему тайлу. AMD не разрабатывает тайловые GPU, их GPUs известны как forward или immediate renderers. Это означает что когда приходит команда нарисовать какую-то геометрию, GPU рендерит ее целиком, куда бы она ни попала и завершает ее обработку до перехода к следующей команде. Это идет конвейером, команды могут пересекаться и даже завершаться вне очереди, но есть встроенные в GPU аппаратные механизмы, позволяющие получить данные обратно в правильном порядке, прежде чем эти данные будут записаны в память, так что драйвера (AMD) в целом не должны волноваться об этом. Так как же эти renderpass-объекты взаимодействуют с нами и почему это нас заботит?
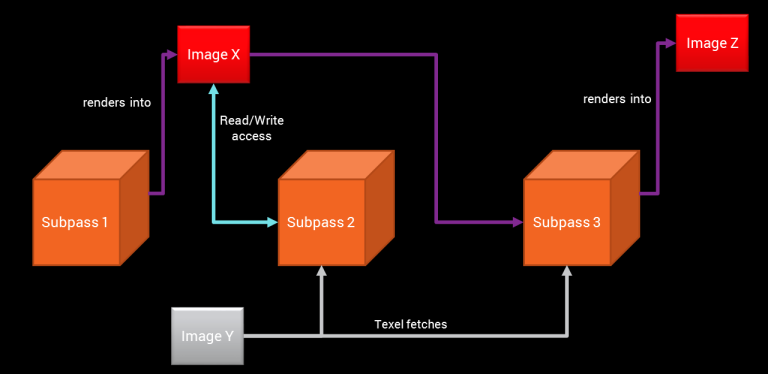
В Вулкане объект renderpass содержит структуру кадра. В простейшем случае, renderpass инкапсулирует набор вложений буфера кадра (framebuffer attachments), базовую информацию о состоянии конвейера. Однако, renderpass может содержать один или более объектов subpass и информацию о том, как эти subpass-объекты связаны друг с другом. Это то, что нас и интересует.
Каждый из объектов subpass может ссылаться на имеющиеся вложения буфера кадра для чтения и записи. Вложения, доступные на чтение, это входные данные, и фактически содержат результаты ранних subpass в этом же пикселе. В отличии от традиционной техники рендеринга в текстуру, где каждый проход мог читать любой из пикселей предыдущего прохода, входящие вложения гарантируют что каждый из фрагментных шейдеров получит доступ только к данным того же пикселя. Кроме того, каждый subpass содержит информацию о том, что вначале делать с каждым из аттачментов (очищать, восстанавливать из памяти или оставить не инициализированным) и что делать с ними в конце (сохранить их обратно в память или выкинуть). Зависимости между subpass-объектами явно прописывается приложением, это позволяет тайловому рендеру точно знать когда очистить тайловый буфер, восстановить его из памяти и т.д.
Go Forward Faster
Как выяснилось, форвард рендер так же может использовать эту информацию в своих интересах. Вот несколько примеров оптимизаций, которые можно сделать. Подобно тому, как мы можем сказать, что один subpass зависит от результата более раннего, мы можем сказать, когда subpass не будет зависеть от более ранних. Таким образом, иногда мы можем рендерить эти subpass-ы паралельно или даже в произвольном порядке и без синхронизации. Если subpass зависит от результатов предыдущего subpass-а, то традиционные API вставляли в конвейер GPU заглушку, чтоб синхронизировать выходные кэши бэкэнда с кэшами входных текстурных юнитов. Однако, при перепланировании задач, мы можем дать инструкцию рендер бэкэндам сбросить свои кэши, не связанных с процессом заданий, затем сбросить текстурные кэши перед инициализацией соответствующего subpass-а. Это убирает заглушки и сохраняет время GPU.
Так как каждый subpass включает информацию о том, что делать с аттачментами, то мы можем сообщить что приложение собирается очистить вложения, или что его не волнует содержимое этого аттачмента. Это позволяет драйверу запланировать очистку задолго до начала реального рендеринга, или принять разумное решение о том, какой из методов будет использован для очистки аттачмента (такой как использование вычислительного шейдера, аппаратную функцию или механизм DMA). Если приложение сообщает что ему не нужны аттачменты чтобы иметь определенные данные, то мы можем перевести вложение в частично-сжатое состояние. Это когда сами данные не определены, но его состояние требуется железом для оптимального рендеринга.
В некоторых случаях, структура данных в памяти отличается для оптимального рендеринга и чтения через текстурные юниты. На основе анализа зависимостей данных, предоставляемых приложением, драйвера (AMD) могут принять решение о том, когда лучше выполнить изменение структуры данных, распаковать их, изменить формат и т.д. Это так же может разбить некоторые из этих операций на две фазы, чередующиеся с поставляемыми приложением задачами, что так же устраняет заглушки в конвейере и повышает эффективность.
И, наконец, Вулкан включает в себя понятие переходных вложений, это те аттачменты буфера кадра, которые в renderpass-е изначально находятся в неинициализированном или очищенном состоянии, записываются одним или несколькими subpass-ами, используются одним или несколькими subpass-ами и в конечном счете отбрасываются в конце renderpass-а. В этом сценарии данные в аттачментах существуют только внутри renderpass-а и их не нужно записывать в основную память. Не смотря на это, все так же нужно выделять под них память как для вложений, хотя данные никогда не покидают GPU, живя вместо этого только в кэше. Это экономит пропускную способность, снижает задержки и повышает энерго-эффективность.
A First-Class Feature
Не нужно рассматривать renderpass-ы как фичи только для мобильных устройств. Это первоклассная возможность API Вулкана, которая предоставляет множество возможностей для оптимизации и повышения эффективности на GPU, даже для форвард-рендеров. Драйвера AMD уже включают в себя компилятор renderpass-а, в котором уже реализованы некоторые и оптимизаций, описанных выше и у них на тестировании находится длинный список фичей, которые будут добавлены в драйверй в ближайшие месяцы. Простая комбинация нескольких проходов в один subpass вероятно не принесет существенного улучшения, однако, возможность получить ваш фрейм внутри нескольких renderpass-объектов потенциально может привести к огромному выигрышу в производительности аппаратного и программного обеспечения.
Комментариев нет:
Отправить комментарий